This post will detail and summarize the key architectural considerations and findings based on the experience of moving several environments from one of the usual hyperscaler-suspects like AWS/Azure/GCP to a self-managed, but still cloud hosted solution based on the Hetzner Cloud. The goal is to show the different considerations before attempting such an approach, as well as an exemplary target architecture.
Initial scenario
The assumed scenario for this post is loosely based on a real migration, from GCP but can easily be adapted to other situations. The system we are talking about consists of ~20 services and ~2 jobs executed by Google Cloud Run, a read-heavy ~300GB PostgreSQL database and some auxiliary services like Redis, MongoDB, etc. Initial starting point for the project was to reduce the monthly cloud costs, which where especially substantial for the managed database. Potential target for the initial evaluation was the Hetzner Cloud offering.
Comparing the clouds
To paraphrase a quote of unknown origin
There are no solutions, just tradeoffs. Don’t think there’s a perfect tech stack.
comparing the available building blocks of the Google and Hetzner Cloud it is quite obvious, that the latter needs some significant work to reach feature parity with the currently used Google services to run the setup that should be migrated.
missing features
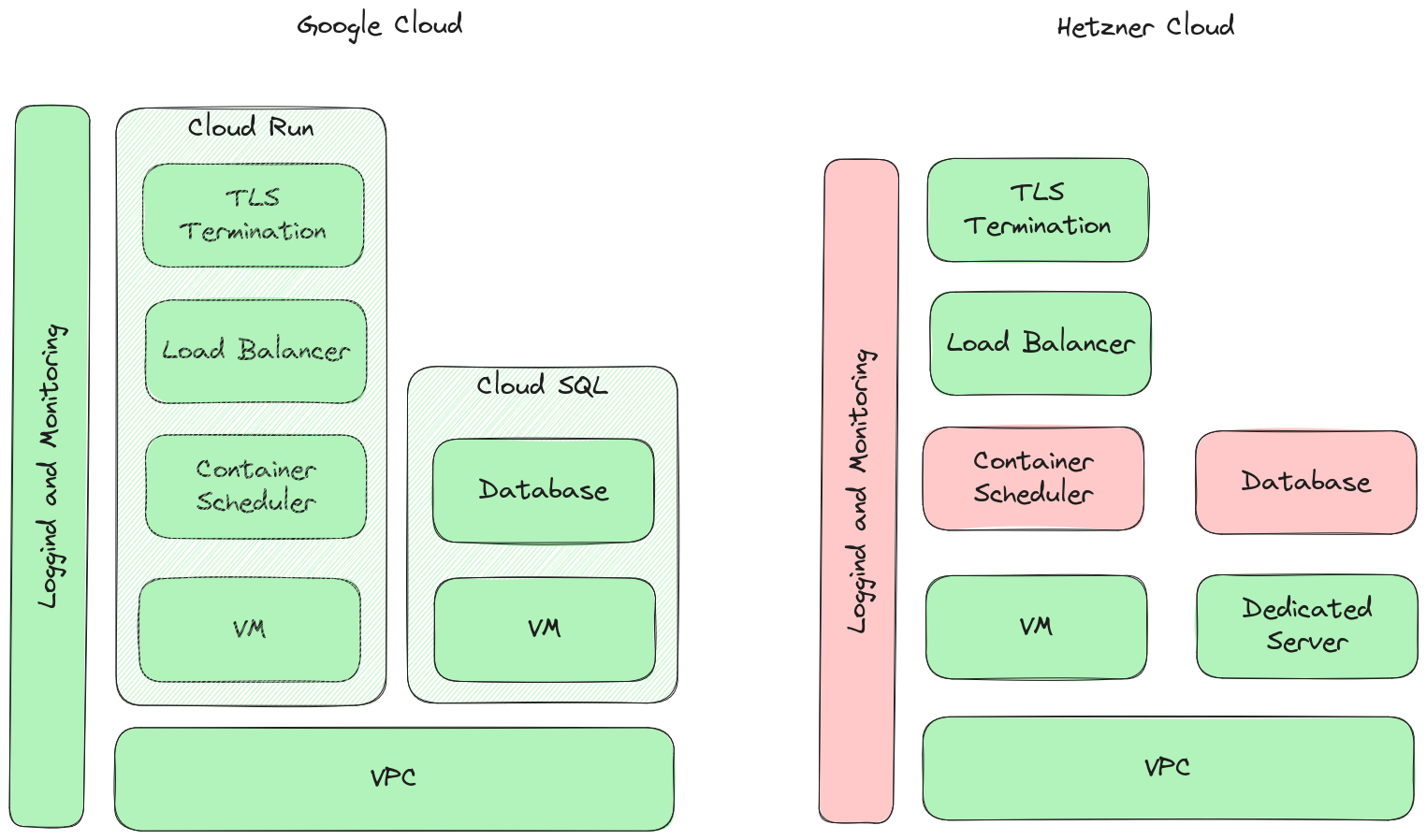
Generally speaking the biggest tradeoff decision to make here was to weigh up the additional engineering cost and operational overhead needed to close the gap of different abstraction levels between the clouds. As always this is not a black/white decision but depends on several considerations:
-
Scalability What load, and in particular what load patterns need to be handled? Big traffic spikes might mean additional engineering for automatic scaling capabilities. Also, the geographic distribution of the load is important, i.e. do we need to server multiple regions (Americas, Europe, Asia, …) to lower latencies or can we get away with a single zone deployment?
-
Cost Efficiency This is kind of a grey area, because of the already mentioned tradeoff between additional engineering and abstraction. On the raw pricing-per-specs level though it’s a little bit easier e.g. to compare a managed Cloud SQL instance in Frankfurt with 24 vCPUs, 128Gb memory and 2TB storage at ~2000€/month, to a dedicated EX130-S server for roughly ~150€/month
-
Managed Infrastructure This is also an important point to consider, not so much for the VMs because the underlying systems are fully manged in both environments, but if dedicated hardware comes into the equation we have to consider the possibility that we might need to deal with failing disk drives, memory or basically anything else that can break on a modern system.
-
High Availability and Redundancy Major cloud providers offer geographically distributed services with built-in failover, disaster recovery, and redundancy. This means your services are more resilient and have higher uptime compared to self-hosting again of course with an attached price-tag.
-
Security and Compliance Cloud providers often have extensive security measures and certifications in place. They also provide tools to help meet compliance requirements like GDPR, ISO-27001, etc.
-
Automatic Software Updates and Patching Cloud providers handle software maintenance, ensuring that your services are always up-to-date with the latest features and security patches, which we would need to replicate for the self-managed part of our stack in the Hetzner cloud.
-
Observability The Google cloud platform offers a tightly integrated observability stack well integrated into all services. Logging and metrics will be even more important when we need to do parts of the operations for ourselves, so we need to find a replacement here as well.
-
Operational experience The operational experience of the people that have to operate and maintain the solution is another important consideration, because they now need to care for more layers of the overall architecture instead of just pointing a container scheduler to a new docker image.
-
Backup and disaster recovery Especially when looking at dedicated machines we need to think about backup and disaster recover scenarios. Despite all redundancy, Raid and clustering, it is still possible to lose data due to hardware failure, misconfiguration or operator error. In a cloud scenario we would just revert to the latest backup, which is a safety net we definitely also want to have in the new solution.
Making Tradeoffs
When asked how the future architecture should look like, its hard not to answer with the default consultant answer of “it depends”, but it really depends on the individual circumstances of each project :-).
As an example lets have a look at the possible replacement for Cloud SQL in our self-hosted scenario
potential database setups

- The simplest solution is a single VM with some attached storage that hosts the database instance. Easy to deploy with Terraform, simple to debug because it’s just a single machine if in doubt we can just SSH into the machine and look around. On the downside if the machine dies the database is unavailable, and we need to manually intervene to fix the issue. We are treating mean-team-to-recovery (MTTR) here for complexity to get a simpler system
- The next option would be a two-node database setup with a primary and a replica following the primary. This is a little bit more complex to set up operate and monitor but gives us some leverage in case the primary dies, because we can then manually promote the replica to primary and switch over services to the new primary reducing the MTTR
- We can even take this a little bit further and use a proxy in front of the database like pgbouncer or similar to make the switchover in the failure case faster, shaving off some more time of the MTTR but trading in a little bit more complexity
- Now the next step would be a multi-node setup with automated failover, for example with patroni or similar systems, to reduce MTTR and MTBF. But again with have to pay in added technical and operational complexity
- The non-local attached storage volume for Hetzner cloud VMs are a bit limited in terms of IOPS, so if the performance requirements are a higher we might need to opt for dedicated machines do deploy the database solution, adding another level of complexity to the solution because we now also need to factor in the possibility of hardware failures in our MTTR/MTBF equation
Those considerations need to be made and carefully balanced for all aspects of the intended target solution, and it is impossible to decide without knowing the full context of a particular project.
Solution architecture
After balancing pros and cons for the full stack, this is an exemplary overview of a final architecture. Of course this only highlights the key-parts of a possible solution, and should not be taken as a blueprint in other situations.
Infrastructure as Code
To ensure consistency, avoid configuration drift and to support different environments like test and prod as a first class citizen, of course the solution it implemented using an infrastructure as code approach.
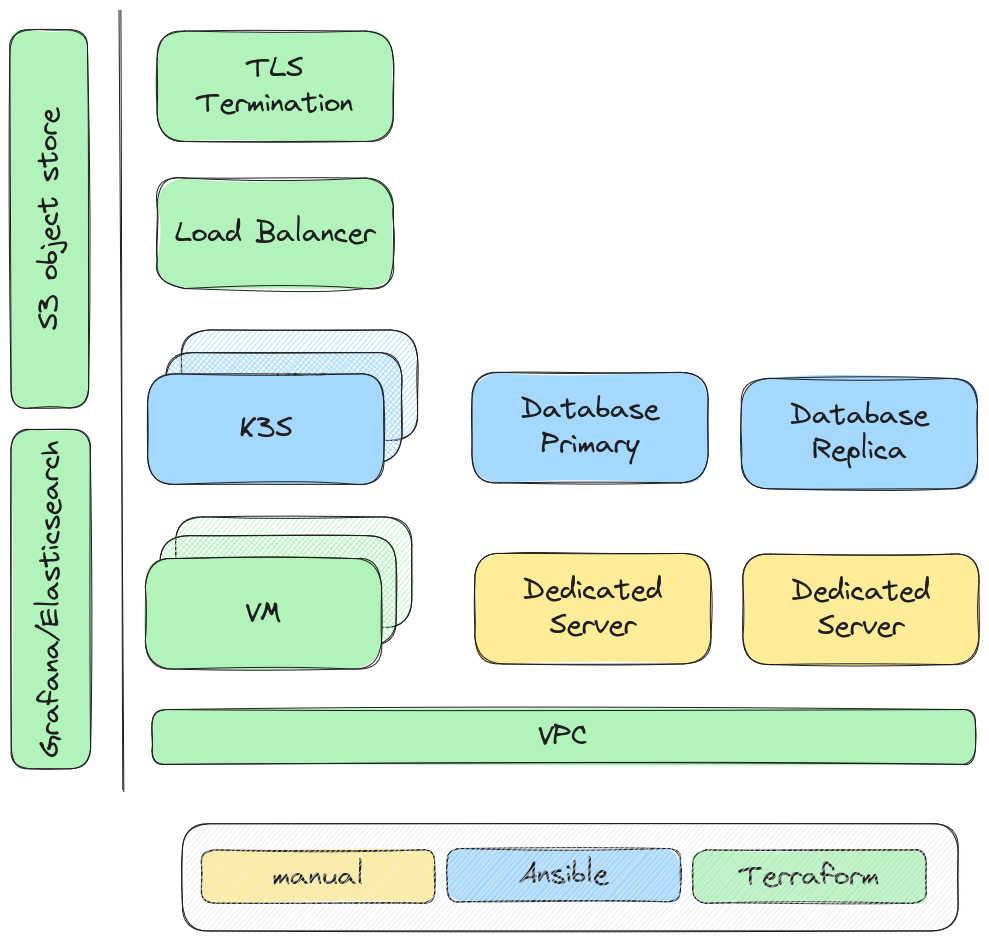
- Terraform provisioned Hetzner cloud and external resources (Elasticsearch, Backup S3 buckets, …)
- Manually managed dedicated servers attached to the same network for private local traffic via vSwitch
- From OS level upwards everything is provisioned using Ansible, both for dedicated servers and cloud VMs
- Big community with mature solutions for common problems readily available (updates, ssh-key distribution, firewall, etc.)
- Regular security updates also orchestrated with Ansible, triggerd by CI/CD pipelines
Container orchestration
Despite the (to some degree legitimate) reputation of being too complex for small deployments, K8S will serve as the container scheduler solution for running services and jobs.
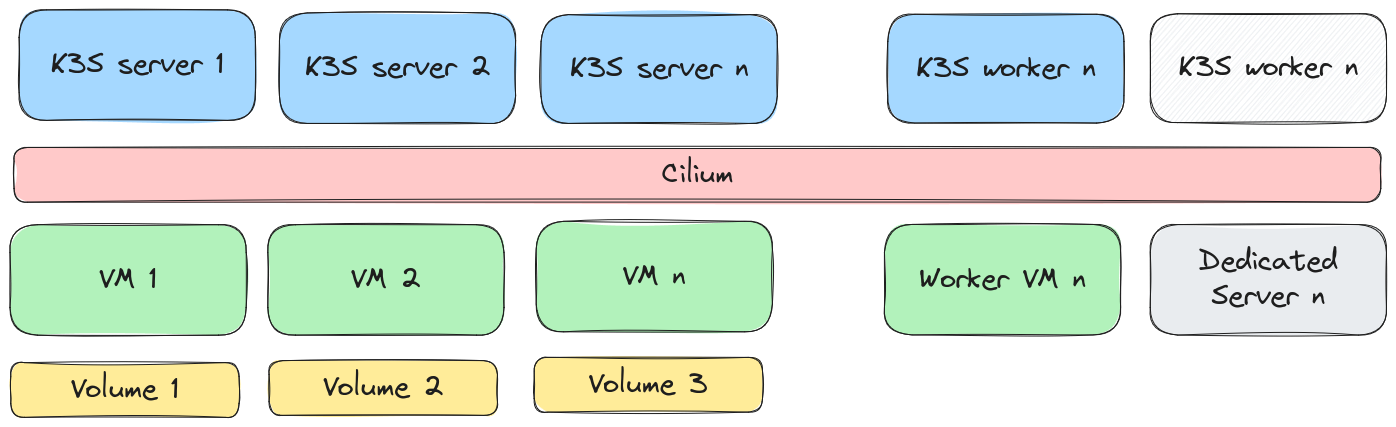
- Relatively lightweight K8S implementation based on K3S
- Less complex to set up and debug compared to a full-blown K8S solution
- Huge mind-share due to wide adaption helps with issues and bugs
- Integration with Hetzner cloud resources via Hetzner kubernetes cloud controller
- K8S as de-facto standard for container orchestration as of now a relatively safe bet, could make future migrations to other clouds easier
- A lot of the needed axillary tooling is available in the form of mature operators/helm charts (redis, mongodb, …)
- Solid tooling and lots of documentation available for day-to-day operations (K9S)
- Setup can slowly grow, by splitting up the single binary K3S components into dedicated individually scaled services if needed
- Cilium network layer for pod communication, network policy enforcement and encryption
Networking
The network setup aims towards keeping all traffic local to the private network minimizing the public surface. Compared to the Google Cloud solution though, at least the SSH port needs to be exposed for management purposes.
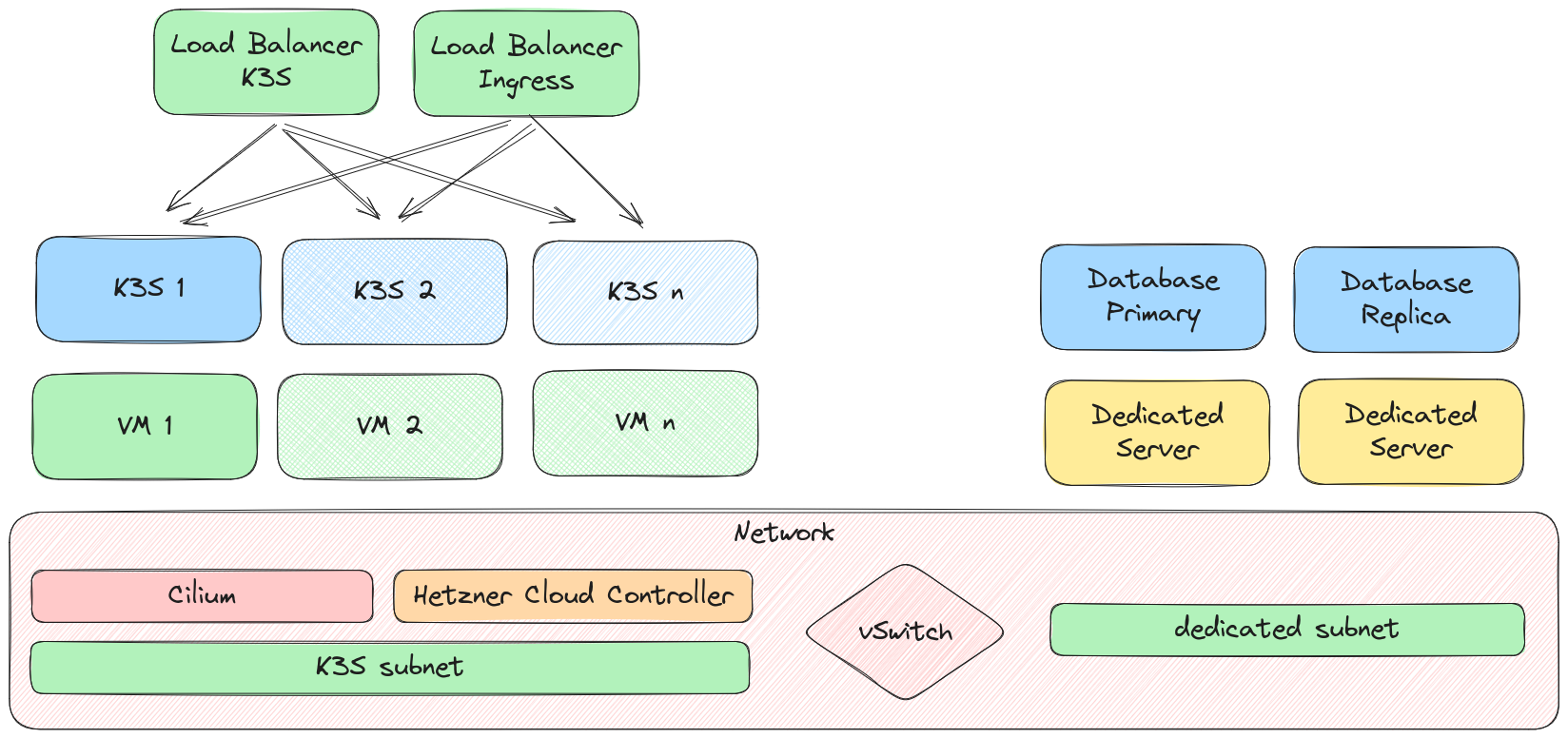
- Cilium as network plugin for pod/node communication
- Good performance thanks to eBPF based implementation
- Provides decent debugging tools for network debugging and logging with hubble
- Good integration in K3S and the Hetzner kubernetes cloud controller for local routing in private Network
- All server-to-server traffic is routed via private network
- Only SSH/Ingress and K3S control plane is reachable from the outside
- Ingress and control plane is distributed via Loadbalancer
- K3S control plane could also go private, but with an impact on ergonomics for day-to-day operations
Database
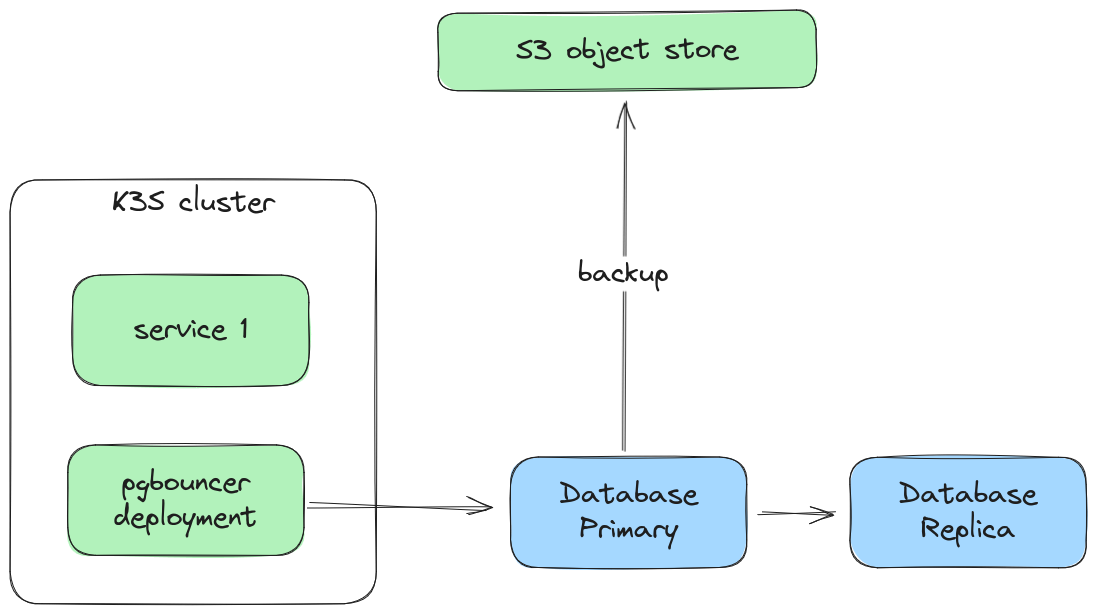
- Performance requirements mandate usage of dedicated machines
- Primary/replica setup with pgbouncer as frontend is a manageable setup that can grow into more automated (complex) setup when operational experience grows
- Switchover can be orchestrated with Ansible with only minimal needs for manual interaction, or fully automatic if shorter MTTRs are required
- Backup to non-Hetzner cloud S3 bucket using pgbackrest
- Cloud-external backup reduces blast radius in case of accidental resource deletion adding another safetynet
Observability
- Metrics and logs from all servers collated with metricbeat and filebeat
- Wide range of supported collectors for components like PostgreSQL, Redis, etc.
- Data is shipped to dedicated elastic.co instance
- Grafana would also have been an option, but the way logs can be analyzed in Elasticsearch resembles Google Cloud logging, providing some kind of commonality
Operations
- During initial system bootstrap, do it manually first and automate afterward to gain confidence and understanding of the whole system
- Fire drills to gain experience and train day-to-day operations
- Experience incident look-and-feel in monitoring and on the servers when they are happening
- Learn how to fix the issue, using either manual intervention or IaC
- Example drills
- Randomly delete a K3S cluster node and recover
- Delete/corrupt database data from primary and restore from backup
- Delete whole environment and restore everything from backup
Closing thoughts
Migrating away from the big hyperscalers is not an easy lift-and-shift operation, but requires in depth analysis of the whole stack, and a solid understanding of the technical details as well as operational experience, especially when moving to a cloud that only offer a basic set of building blocks.
When done right, it can (by trading in some extra engineering) save a substantial amount of cloud costs and also remove some vendor lock-in, allowing for a wider range of provider options. A key point to reduce complexity and operational workload is to prefer mature battle-tested tech that may look boring and less appealing but rewards you with simpler systems that are easier to operate and maintain.
If you need help with your project, I am happy to help.